
如果你想跟罗辑一起更深入地学习系统设计,有兴趣的同学报名参加爱思备受好评的系统设计模拟面试服务以及系统设计直播课,由作者本人为同学们教学,力求给大家带来最深入的系统设计高频题讲解以及最针对面试实战的技巧解析,帮助同学们举一反三,高效准备面试。
 罗辑
罗辑 罗辑
罗辑
1. 什么是 Kafka
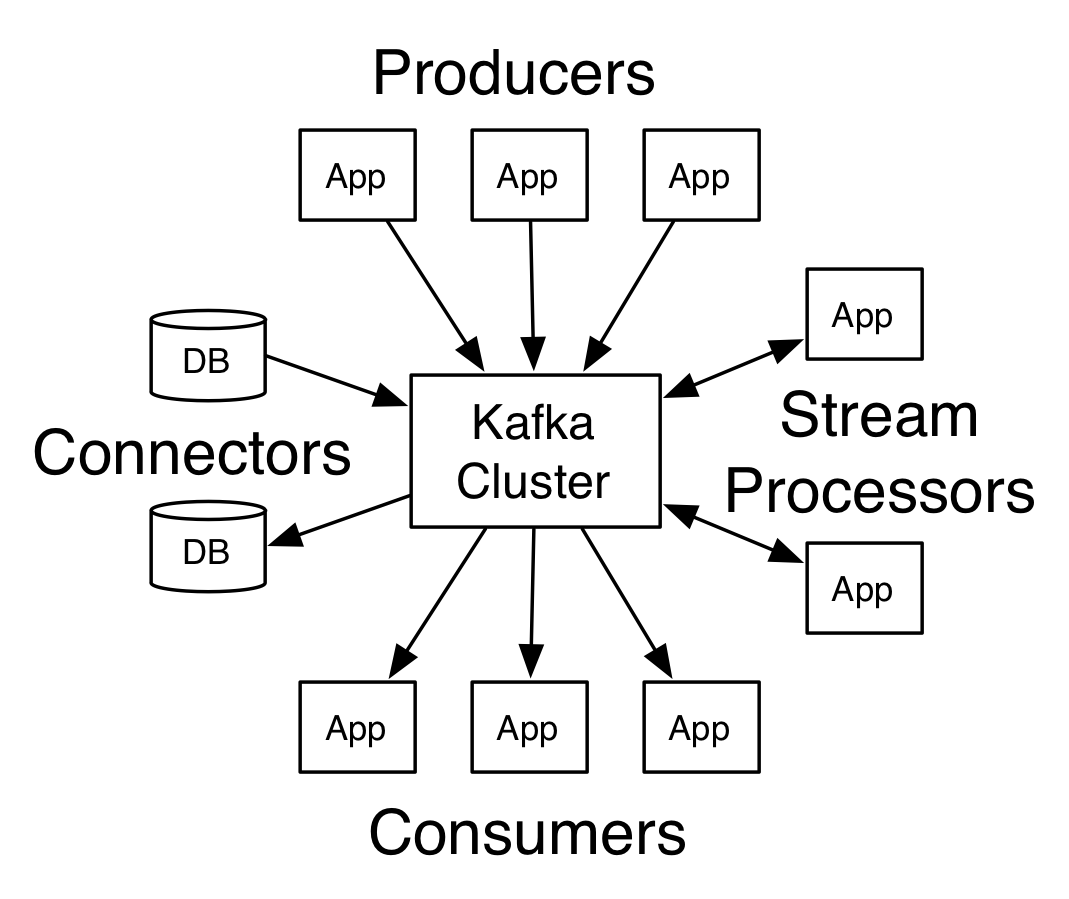
Kafka 是当今非常流行的分布式流处理平台,通俗点来说,Kafka 不仅仅是可以用作Message Broker,它还挺提供一些额外功能:
- 可以在一定时间内存储信息 (Store)
- 对信息进行实时处理 (Process)

正是因为提供了以上两个额外功能,Kafka可以在支持传统 Message Broker 的使用场景(在不同系统之间传递信息)以外,还能支持针对信息流的反应和变换。下面的小节会对存储信息和实时处理两个额外功能做仔细的讲解。
2. Kafka 的起源故事
Jay Krep,Kafka 的主要作者之一,在他的文章中解释了 Linkedin 设计 Kafka 的初衷。他所描述的应用场景是很有代表性的,能很好的解释 Message Broker 给一个大型服务的价值。我们就借这此给上一节做一个实例。
最开始的时候,Linkedin 希望可以使用 Oracle Data Warehouse 内的信息拷贝出来,到 Hadoop 上做一些处理。在这个过程当中,他们的工程师发现了这个项目的几个特点以及潜在延伸。
- 花了大量的时间来确保数据转移的稳定性,因为一旦数据转移过程中出现任何问题,之后 Hadoop 的分析就变得无意义了。
- 新的数据源需要大量时间去配置,这很不理想。解决方法是对所有的数据系统的接口都标准化,使 Hadoop 系统可以自动加载数据。
- 有大量的其他组的数据源希望被整合到系统里来,因为将分散在各个不同服务上的信息整合在一起可以实现很多本来无法做到的分析,会帮助所有的参与者。
- 即使有大量数据源被整合,要达到数据全覆盖仍然很难,所以我们要进一步将数据源整合的工作简化。
- 接收端除了 Hadoop,还可以包括很多其他系统如 Monitoring 和 database。
- 发送端除了Oracle Data Warehouse,还可以包括 Voldemort (key-value store), Espresso (Document Store) ...
如果使用最粗浅的做法,要实现多对多的全覆盖,需要总共 O(N^2) 个数据流。这是不可以接受的。
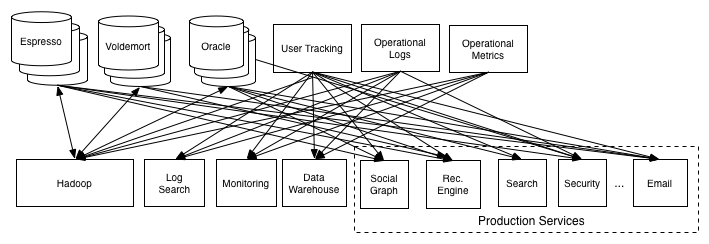
然而一个中介 - Message Broker 可以大大简化各个系统内部处理数据流的工作,将其限制在每个服务一个数据流。

3. 信息传递
Topic 是 Kafka 的核心概念,它描述信息流的类别名称。信息传递的开端是Producer 将信息发送到特定的 Topic。
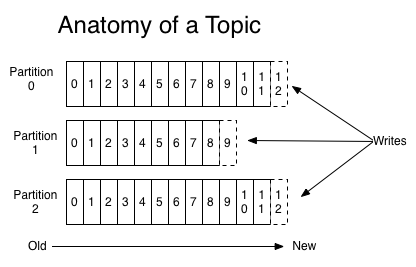
针对特定的 Topic,Producer 可以将信息写到多个 Partition,信息在 Partition 内部保证顺序。Producer 可以简单地轮流 (Round-Robin) 将信息发送到不同 Partition中,也可以基于信息中内容发送到特定的 Partition。
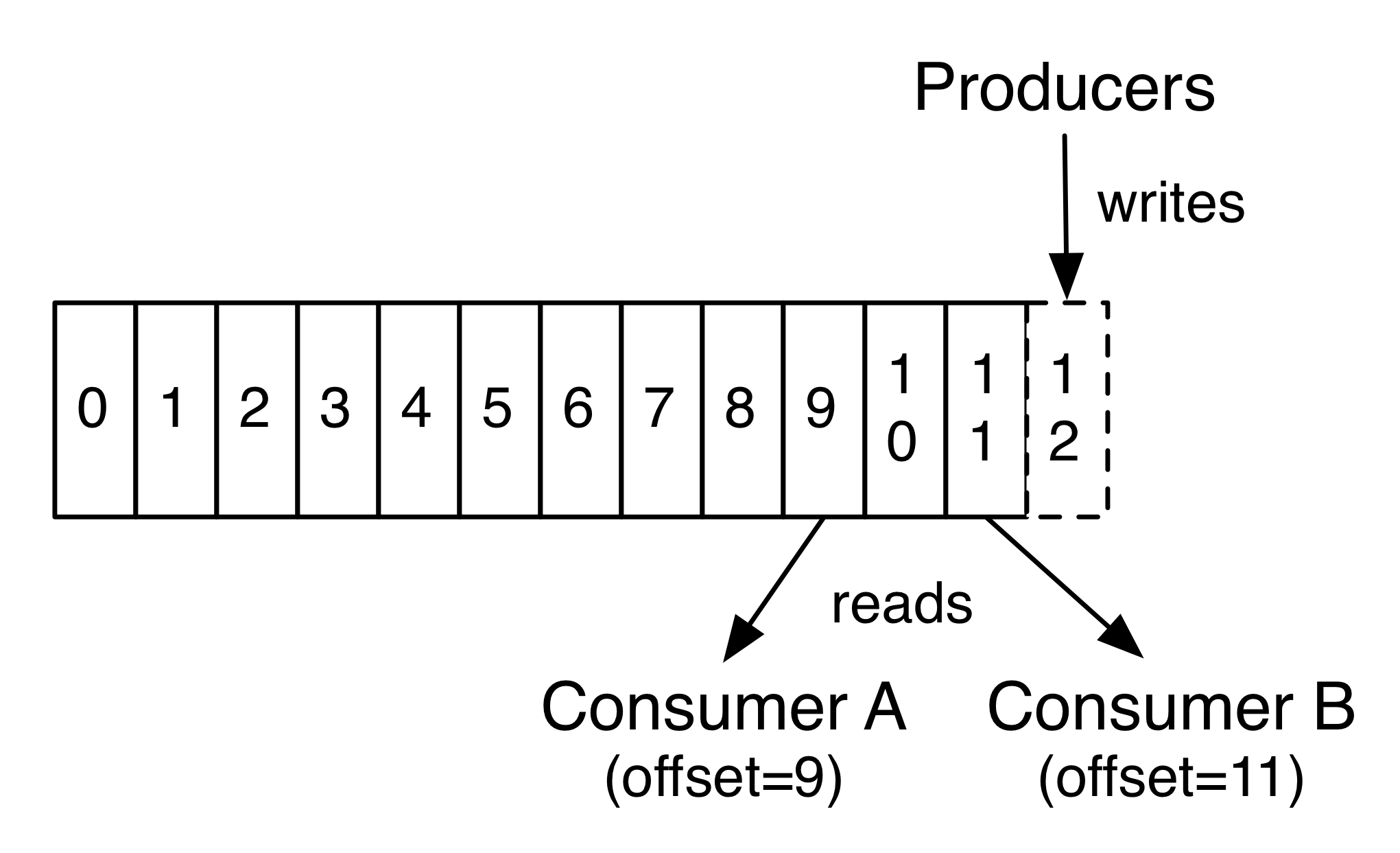
Consumer 维持的唯一一个状态是图中的 Offset,Consumer 基于此控制从 Log 的什么地方开始读取。
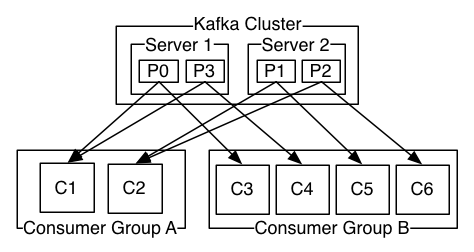
单个Consumer Group中的所有Consumer会合力读取信息。每个Consumer Group之间互相独立,分别读取所有信息。
4. 设计思想
Kafka的核心抽象是日志 (Log)。当我们试图要理解 Kafka 的设计思想的时候,我们可以简单回顾一下日志的特点。
日志是最最简单的存储机制,包含一段只能添加,不能更改的按照时间顺序排列的信息。拆解开是以下几点:
- 写总是发生在末尾,而读总是依次从左往右,不需要乱序读取 (Random Access)。
- 每条信息的序号可以用来表达时间的先后。
我们再往下挖掘一层,拥有以上性质的日志可以用来干什么呢?日志可以用来记录变化。
- 源代码版本控制系统使用日志来记录每一个历史版本的信息
- 容灾机制使用日志来恢复系统原本的状态,如数据库
- 分布式系统使用日志来将信息更新到备份机器上
看到这里,聪明的同学们可能想到了大家更熟悉的数据库 - 数据库记录状态,日志记录变化。以上的三个例子都是通过日志记录的变化,基于一个原始版本产生一个或者多个历史版本。抽象一点说,日志记录变化等效于记录所有的历史版本,这是记录状态的数据库无法做到的。
看到这里,同学们可能有点云里雾里,头上冒问号 - 这一堆跟 Kafka 有什么关系?
日志作为 Kafka 的核心抽象,在流处理中有两个非常棒的特性。
- Producer 产生的信息可以以不同的速度被多个 Consumer 处理
- 正是因为日志记录了变化以及变相记录了所有历史版本,才使得 Producer 和 Consumer 有了很高的自由度去按照自己的节奏发送和处理信息,做到更高一级别的解耦 (Decoupling),为更大规模的 Scaling 打下基础。即使 Consumer 宕机,信息也不会丢失。
- 数据结构直接存储在硬盘上
- 因为读取的模式很单一,尤其是不需要乱序读取。便宜的硬盘 HDD 的读取速度在顺序情况下可以达到200MB/s,这个速度在下游需要针对每条信息做处理的情况下已经足够了。(作为对比,DRAM 可以达到2-20GB/s)
- Kafka 因此可以保存时间长的多的数据,而不需要立刻删除处理完的数据。
5. RabbitMQ vs Kafka
之前我们学习了 RabbitMQ 就是一个传统意义的 Message Broker。其核心抽象是队列(Queue)。
罗辑
我们可以通过比较它们来加深我们对 Kafka 的理解。
| RabbitMQ | Kafka | |
|---|---|---|
| 性质 | Message Broker | 分布式流处理平台 |
| 信息保留时间 | Consumer读取完毕信息即删除 | 较长,由Producer配置 |
| 信息存储 | 内存,可选硬盘备份 | Log + Index 在硬盘,Index同时存入内存 |
| 信息读取 | Push to Consumer | Consumer pulls |
| 信息顺序 | 单一consumer时保证顺序 | Partition内保证顺序* |
| 信息次数 | 至多一次 或 至少一次 | 至多一次 或 至少一次 或 不多不少一次 |
| 信息优先级 | 可配置信息优先级 | 不支持 |
| 性能 | 中 | 极高 |
| Consumer | 所有Consumer合力读取信息 | 每个Consumer Group分别读取信息 同个Consumer Group中的Consumer合力信息 |
我们仔细分析就会发现当中的信息保留时间,存储和读取上的区别就是这个核心抽象不同而导致的。
6. 实现细节
6.1 Scalability
- Partitions 会被分散到 Kafka Cluster 的多台机器上做信息处理以及接受请求
- 每个 Partition 可以被复制到多台服务器上来保证容灾需求
- 每个 Partition 有一台机器作为 Leader,其他机器作为 Follower。Leader 处理读写需求,Follower 复制 Leader。如果 Leader 宕机,Follower 会被晋升为Leader。
- Kafka 使用 Zookeeper 来协调 Kafka Cluster 中的机器。
- 在同一个 Consumer Group 里,一个 Topic 只能支持至多数量跟 Partition 数量一样的 Consumer。
下面我们看一下读写的具体例子。
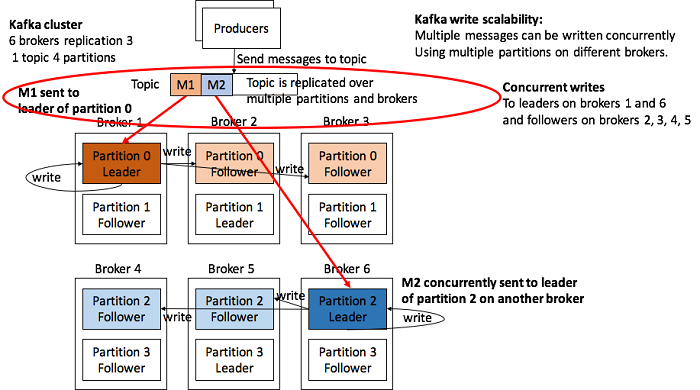
从写的角度上,Topic 里的信息会被分散到不同的 Partition Leader。Partition Leader 更新对应的 Follower。
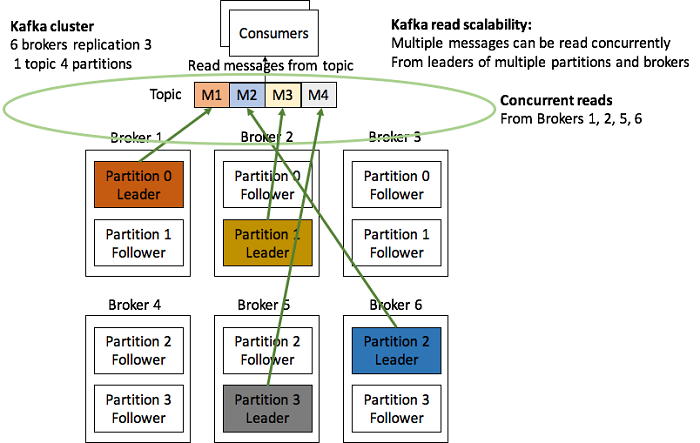
从读的角度上,Consumer 可以分别从各个 Partition Leader 那里同时读取信息。注意之前提过的“在同一个 Consumer Group 里,一个 Topic 只能支持至多数量跟 Partition 数量一样的 Consumer。”,这意味着所有 Consumer 都可以同时参与读取。
总结起来说,Kafka 可以具有极好的 Scalability。然而这还是依赖于使用者根据 Producer 和 Consumer 的数量合理地配置较多的 Partition,使 Kafka 自带的Scalability 可以发挥出来。
6.2 数据结构
之前提过 Kafka 的核心数据结构是日志。下面我们来看一看这个日志的实现。
回顾一下前面的内容,每个 Topic 可以分成多个 Partition。当最早的信息需要每个一段时间被删除的时候,修改文件是很麻烦的。于是 Kafka 引入了 Segment 的概念,一个 Partition 可以被进一步地分割成 Segment。
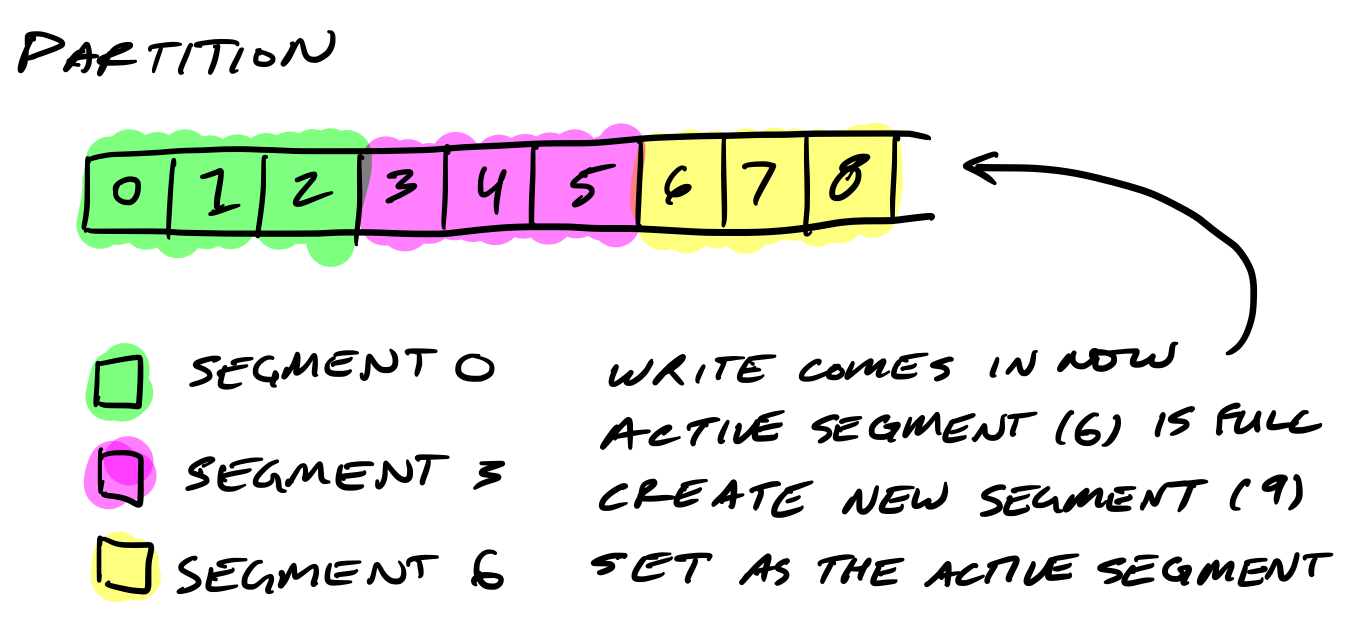
当需要向一个 Partition 写信息的时候,实际上我们是写在最后一个还未写完的 Segment 上。当前一个 Segment 写完之后,新的 Segment 会生成,由它的 Offset 来命名。
说完了概念,我们看看 Partition 和 Segment 如何对应到文件系统中。
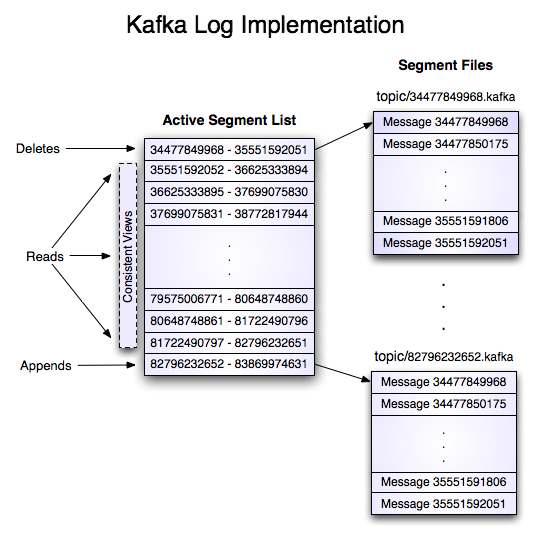
在文件系统中,Partition 是目录名,而 Segment 是文件名。每个 Segment 有 index 和 log 两个文件。后者包含具体的信息本身和元信息。
$ tree kafka | head -n 6
kafka
├── events-1
│ ├── 00000000003064504069.index
│ ├── 00000000003064504069.log
│ ├── 00000000003065011416.index
│ ├── 00000000003065011416.log
Index文件在内存中有副本,在Consumer上线时帮助定位读取的起始点。

7. 高级API
Kafka 在传统 Message Broker 提供的 Producer API 和 Consumer API 基础上,额外提供了一些高级 API。它们延伸了传统 Message Broker 的功能,提供了更高一层的抽象,使得用户在使用接口时更加方便。
7.1 Kafka Streams
7.1.1 概述
Kafka Streams 方便了对信息实时处理 (Process)。
Streams 这个名字起得很形象,描述一条无始无终的信息流。每一个单独的信息称为一个 data record,实现上是键值对 (Key-value Pair)。
下面是它的主要特点。
- 作为客户端的库 (Client Library), 直接跑在客户端上,而不是 Kafka Broker 集群上
- 跟客户端一起 Scale
- 保证每条信息处理一次,不多不少(即使客户端和 Kafka Broker 出现问题)
7.1.2 信息流处理 (Stream Processing)
这一小节我们深入看一看 Kafka Streams,也就是 Kafka 做信息处理的高级 API,是怎么方便用户的。
下面总结了 Kafka Streams 所支持的操作。
- 支持有状态操作 (Stateful Operation) - 合并 (Aggregations) 以及 加入 (Joins)
- 支持非状态操作 (Stateless Operation) - 比如 映射 (Map) 以及 过滤 (Filter)
- 支持在一定的时间窗口里做有状态操作(比如计数或加总)
- 支持自定义操作 - 使用 Processor API
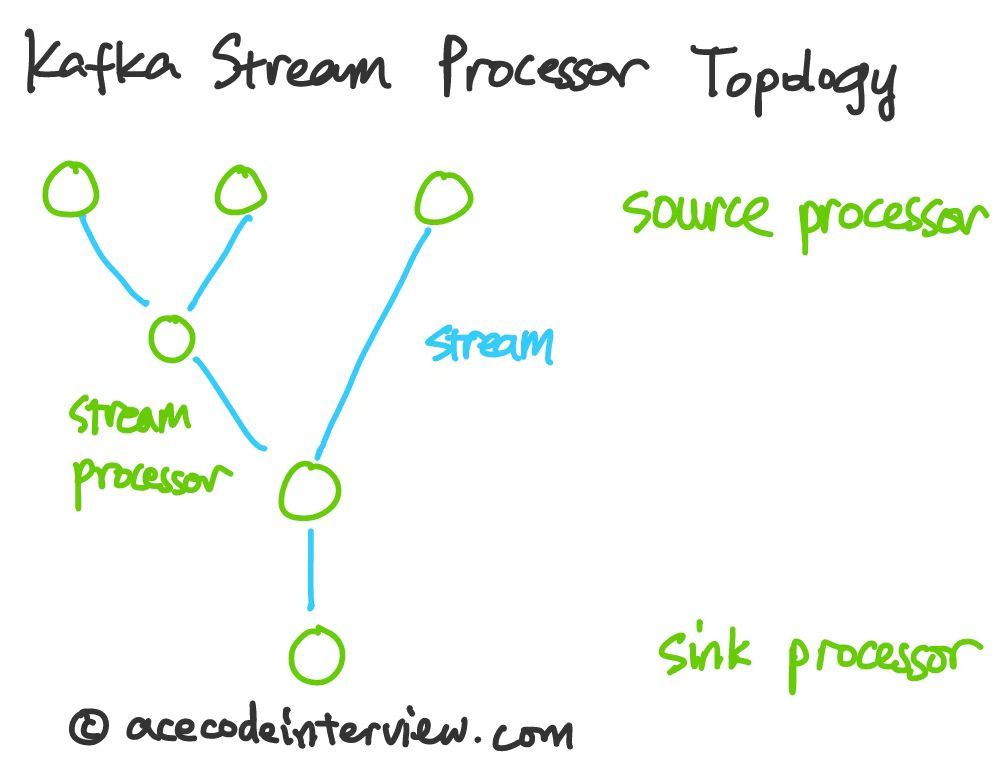
其中每一个中间的 Stream Processor (非 Source 和 Sink) 可以实现上述各类操作,组成一个拓扑图,实现一步一步整合多个信息源的目的。
现在我们思考一下如果我们选用传统的 Message broker,会有什么变化。
我们在很多情况下是有对信息实时处理的需求的,特别是有状态操作。比如,我们想要数一下每一类的信息都有多少个。这个情况下,如果我们用的是 RabbitMQ,我们就得在客户端上实现该逻辑,甚至是分布式版本的该逻辑。另外还需要考虑故障情况下计数的准确性(RabbitMQ 不保证每条信息不多不少只处理一次)。可见,Kafka Streams 提供了相当实用的功能,一个 API Call 就能搞定。
7.2 Kafka Connect
Kafka Connect 标准化了 Kafka 与其他数据系统的接口。
其作用是显而易见的。在第二小节 Kafka 的起源故事中我们就提到过跟不同数据源连接需要大量的工作量,唯一的出路就是标准化它们之间的接口。
Connector 既可以用来从其他数据系统里提取 (Ingest) 数据,也可以用来向其他系统写入数据。
8. 参考材料
- Jay Kreps. (2013). The Log: What every software engineer should know about real-time data's unifying abstraction
- Kafka Documentation. Introduction
- Kafka Documentation. Kafka Streams Introduction
- Kafka Documentation. Kafka Streams Core Concepts
- Kafka Documentation. Streams DSL
- Kafka Documentation. Kafka Connect
- InsideBigData Editorial Team. (2018). Developing a Deeper Understanding of Apache Kafka Architecture Part 2: Write and Read Scalability
- Travis Jeffery. (2016). How Kafka’s Storage Internals Work