

数据库设计中除了对需要存储的信息做合理的抽象以外,最重要的就是根据数据特征和查询模式给特定的列加上合适的键或是索引。这样做的目的有时候是增强数据库的一致性,有时候是提高查询效率,有时候是将数据分布到多个硬盘分区甚至多台机器上。本文就以 MySQL (InnoDB) 为例,讲解 MySQL 中出现的 Clustered Index, Primary Index, Secondary Index, Unique Index, Composite Index, Foreign Key, Partition Key 和 Sharding Key 都是什么含义,如何挑选合适的列以及数据库内部的实现。
由于部分键 (Key) 带有相应的索引 (Index),在某些语境下是同义词(比如 MySQL 的 Query Language 中),特此说明。
如果你想跟罗辑一起更深入地学习系统设计,有兴趣的同学报名参加爱思备受好评的系统设计模拟面试服务以及系统设计直播课,由作者本人为同学们教学,力求给大家带来最深入的系统设计高频题讲解以及最针对面试实战的技巧解析,帮助同学们举一反三,高效准备面试。
 罗辑
罗辑 罗辑
罗辑
1. Clustered Index/Key
Clustered Index 是一个很特殊的 Index,它决定了数据库里数据的物理分布,数据会按照 Clustered Index 的顺序来排布。
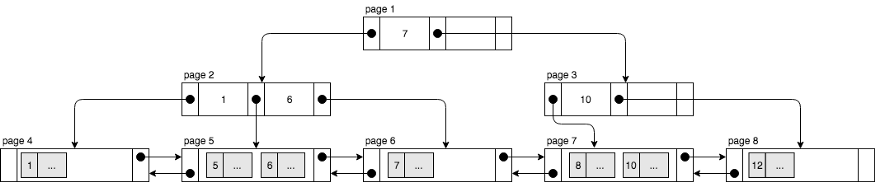
Clustered Index 通常情况下跟 Primary Key 是同义词。更准确地说,如果一个表定义了 Primary Key,那么这个 Primary Key 就会被 InnoDB 来用作 Clustered Index。如果这个表没有定义 Primary Key,那么 InnoDB 会找第一个不含 Null 的 Unique Index 来做 Clustered Index(即该 Unique Index 符合 Primary Key 条件,但没有被明确定义为 Primary Key) 。如果还没有符合条件的那么 InnoDB 会内部生成一个单调递增的列来代表行数,并以此为 Clustered Index。这样做保证了即使没有明确定义的 Primary Key,表仍可以依据选出的 Clustered Index 来实现数据的物理分布。
Clustered Index 按照 B-Tree 形式存储,从而可以在 O(lgN) 时间复杂度内执行指定键的查询,范围查询也只需要锁定第一个存有需要数据的 Page 并向后读取直到完成,不需要做 Table Scan。值得注意的是,B-Tree 的每个叶节点 (Leaf Node) 都包含了行 (Row) 的完整信息。
2. Primary Index/Key
在建表的时候, 用户可以指定 Primary Key,包括使用多个列组成的 Composite Key 来做 Primary Key,但要求 Primary Key 必须是唯一的,并且不含 NULL。如同在 Clustered Index 小节里提到的,如果指定了 Primary Key,那么该列会被用作 Clustered Index。
在建表过程中,选择 Primary Key 是很重要的步骤。下面我们来讲讲该如何选择。
- 虽然表并不一定需要一个 Primary Key,但仍应该尽可能为表选取一个 Primary Key。
- 必须非 NULL 且唯一。
- MySQL 对于整数有优化,所以尽量选取整数型 (INT, BIGINT) 来做 Primary Key。
- 尽量不要依赖已有的列来做 Primary Key (Natural Key),而是选用 Synthetic Key,即自动加一的列。这样做节省 B-Tree 的空间并且避免随机 Insert。同时也可以使 Secondary Index 更紧凑(下一节里会进一步解释)。
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (ID) <- Primary Index
);
3. Secondary Index/Key
所有的非 Clustered Index 的 Index 都叫做 Secondary Index。
Secondary Index 的 B-Tree 物理分布跟 Clustered Index 类似。区别在于叶节点存储有 Secondary Index 到 Clustered Index 的对应关系。在使用 Secondary Index 查询的时候,我们先通过 Secondary Index 找到 Clustered Index,再通过 Clustered Index 找到对应的行 (Row)。
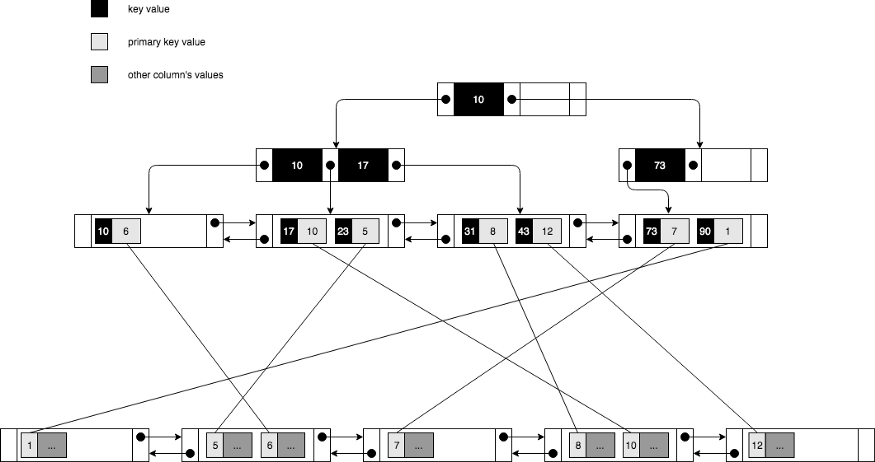
值得注意的是,正由于 Secondary Index 和 Clustered Index 存储在 Secondary Index B-Tree 的叶节点,Clustered Index 数据量越少,Secondary Index 就越紧凑。考虑要数据库可能拥有多个 Secondary Index,Clustered Index 的选取就很重要了,这也是 Clustered Index 一般选取不断加一的列的原因之一。
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PRIMARY KEY (ID),
KEY (LastName) <- Secondary Index
);
4. Unique Index/Key
Unique 是一种加在索引上的限制条件,保证索引列必须是唯一的。Unique Index 允许多个 NULL 值的出现。任何一个 Secondary Index 都可以添加这个 Unique 的限制,这样的话,在添加不唯一的数据进入表的时候就会报错。
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PassportNumber varchar(15),
PRIMARY KEY (ID),
KEY (LastName),
UNIQUE KEY (PassportNumber) <- Unique Index
);
在这里,我们对之前提到的 Primary Key, Unique Key 和 Secondary Key 做一个总结:
| Index Class | Index Type | Stores NULL VALUES | Permits Multiple NULL Values |
|---|---|---|---|
| Primary key | BTREE | No | No |
| Unique Key | BTREE | Yes | Yes |
| Secondary Key | BTREE | Yes | Yes |
5. Composite Index/Key
Composite Index 指的是基于多个列的 Index。该 Index 由指定的多个列的值前后相连 (Concat) 组成,因此,合理设计的 Composite Index 可以加速多种查询。举一个例子,如果 Composite Index 包含三个列,C1, C2 & C3,那么 Index 为 Concat(C1_value, C2_value, C3_value)。查询如果包含 C1,C1 + C2, C1 + C2 + C3,这个 Index 都可以基于本身的排序给查询带来可观的加速。由此可见,Composite Index 的列的顺序是会影响查询效果的,值得仔细考虑。
有时候我们也会听到 Compound Index 的说法,在 MySQL 语境下这不是一个标准词汇,但一般来说跟 Composite Index 是同义词。
CREATE TABLE Persons (
ID int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int,
PassportNumber varchar(15),
PRIMARY KEY (ID),
KEY name (LastName, FirstName), <- Composite Index
UNIQUE KEY (PassportNumber)
);
6. Foreign Key
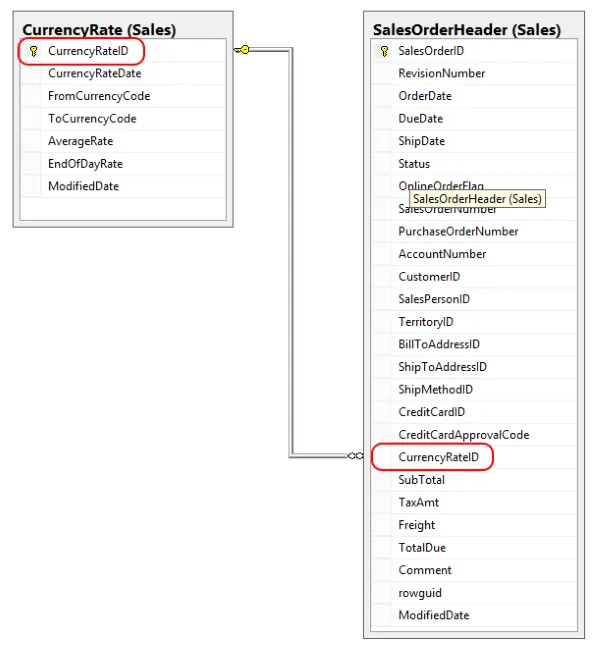
Foreign Key 帮助我们在不同的表之间建立联系。Foreign Key 指代另一张表中的 Primary Key。在表中确立 Foreign Key 能够保证数据的一致性。如下图中 CurrencyRateID 在 SalesOrderHeader 中就是 Foreign Key。
7. Partition Key
下面只讨论 MySQL 意义上的 Partition。MySQL 利用 Partition Key 来将一个表分成多个部分分布文件系统的不同地方。注意这里的 Partition 跟分布式系统中讨论的 Sharding 有所区别。这里的 Partition 更多指的是单机上切分数据。
那么 Partition 有什么好处呢?
- 存储更多数据 - 可以在机器的不同硬盘分区上存储数据
- 方便删除数据 - 没有用的数据可以通过删除整个 Partition 的方法来简单地移除
- 加速查询 - 如果所查询的数据只存在在少数几个 Partition 中,合理设计的 Query 可以只读这些 Partition 而跳过其他
8. Sharding Key
单纯的 MySQL 数据库并不提供分布式的解决方案,也就没有 Shard 的概念。然而,MySQL 官方和第三方提供了一系列分布式方案供用户选择,比如 ProxySQL, Vitess.
Sharding 是一种分布式系统解决的方案,它提供了在不同机器之间分布数据的方法。它采用 Horizontal Scaling 的方法,将数据库按照行 (Row) 来切分,即每台机器上存储了部分行的全部列。Sharding Key 决定了根据什么条件来选择哪些行放入特定机器上,比如依据 Sharding Key 数据的哈希值。
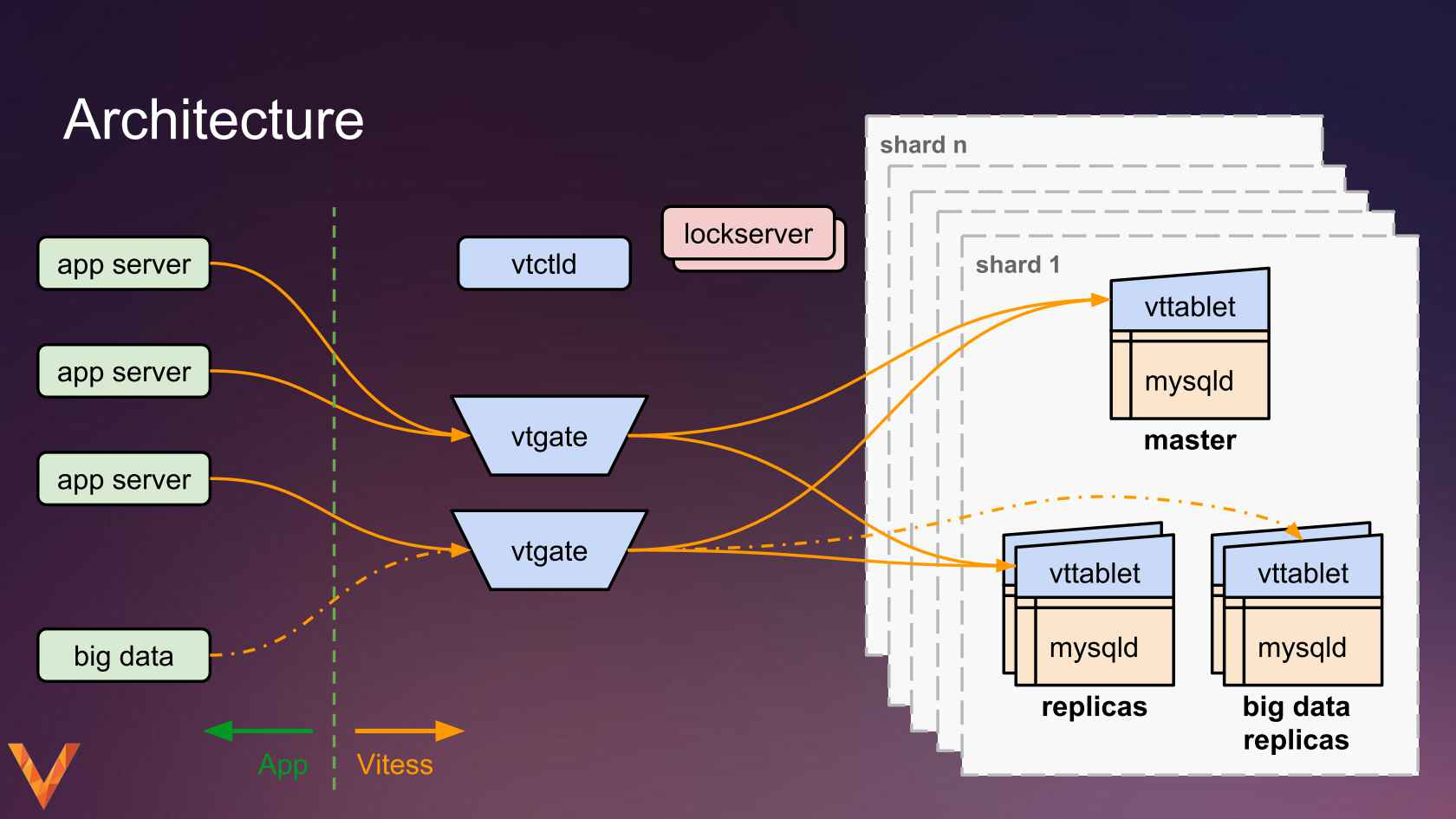
选取 Sharing Key 在分布式系统设计中相当关键,它很大程度上决定了数据库的扩展性 (Scalability)。选取的过程中需要考虑:
- 平均分配读写资源(比如避免使用单调加一的列来做 Sharding Key)
- 平均分配数据存储(避免单个 Shard 体积过大)
- 每次查询访问尽量少的 Shard(降低端到端延迟及服务器负载)
9. 总结
以上总结了 MySQL 各类键和索引的含义,选择标准以及实现方法。这些键和索引的名称在其他 SQL 和 NoSQL 数据库中的含义不一定完全相同但也大体类似。理解了它们之后,相信大家在面试中可以更合理为数据库的列添加这些键和索引,也可以更精准地表达自己的数据库设计想法了。
10. 参考资料
- MySQL 5.7 Reference Manual. 14.6.2.1 Clustered and Secondary Indexes
- MySQL 8.0 Reference Manual. 8.3.6 Multiple-Column Indexes
- MySQL 8.0 Reference Manual. 13.1.15 CREATE INDEX Statement
- MySQL Documentation. Overview of Partitioning in MySQL
- Genchi Lu. (2019). A Brief Introduction to Cluster Index and Secondary Index in InnoDB
- Federico Razzoli. (2019). Why MySQL tables need a primary key
- Sugu Sougoumarane. (2019). Massively Scaling MySQL Using Vitess
- Kris Wenzel. Foreign and Primary Key Differences (Visually Explained)
- nvogel. (2011). In SQL, is it composite or compound keys? - Database Administrators Stack Exchange
- mysqltutorial.org. MySQL Primary Key