

Redis 作为缓存届的招牌,可以说是系统搭建中缓存的默认选项。它的速度很快,配置选项丰富,还包括很多在 Memcached 里需要用户自己处理的功能。对于缓存的基础知识,请参考前一篇 Memcached 内核详解,这里就不多赘述。
 罗辑
罗辑
如果你想跟罗辑一起更深入地学习系统设计,有兴趣的同学报名参加爱思备受好评的系统设计模拟面试服务以及系统设计直播课,由作者本人为同学们教学,力求给大家带来最深入的系统设计高频题讲解以及最针对面试实战的技巧解析,帮助同学们举一反三,高效准备面试。
罗辑 罗辑
罗辑
1. 特点
1.1 速度快
有多快呢?根据2019年的 RedisLab 测试,Redis 在 AWS c5.18xlarge 机器(72 threads)上的最快速度达到每秒 ~5M 操作。
1.2 支持多种数据结构
相对于 Memcached 的单一数据结构字符串,Redis 额外支持一系列的数据结构:
- Hashes
- Lists
- Sets
- Sorted Sets with Range Queries
- Bitmaps
- Hyperloglogs
- Geospatial Indexes with Radius Queries
- Streams
挑几个有意思来讲讲:
- 其中 Sorted Sets 和 Geospatial Indexes 支持查询,这就意味着 Redis 会为这些数据结构编制二级索引 (Secondary Index)。二级索引使得 Redis 的用户可以在 key-value store 基础上添加额外的索引,甚至是组合索引 (Composite index),实现高效灵活的范围查询 (Range Query) 。
- Streams 可以用作 Message Broker,支持类似简化版 Kafka 的 pub-sub 数据传输模式。
1.3 数据持久化 (Persistence)
Redis 不同于 Memcached, 对于存在缓存中的数据提供一系列备份工具,使其具有容灾能力。
可选的持久化策略有两种:
- RDB (Redis Database Backup File) 过一段时间给数据做一个快照 (Snapshot)。
- AOF (Append-only File) 记录每一个写操作,用来复现数据 (Replay)。可以通过设置记录频率来调整数据安全等级。
用户也可以选择跟 Memcached 一样的无持久化,或者同时使用 RDB 和 AOF。
总体上来说,权衡这两种策略,RDB 运行速度更快,数据更小,AOF 更能保证数据的完整性。
值得注意的是,即便 Redis 有持久化选项,我们仍不要把 Redis 当作传统数据库使用,这是一个常见的误区。原因如下:
- 数据需要能够放进内存
- 它只提供 key-value store 的功能以及之前提到的特定的查询模式
1.4 事务 (Transactions)

Redis 支持事务,可以保证事务中的所有命令序列化 (Sequential) 和原子化 (Atomic) 地执行。Redis 提供 EXEC 指令用来执行此前输入的一组命令,如果在 EXEC 指令下达前服务器宕机,那么所有命令都不会进行;如果在 EXEC 指令下达后服务器宕机,那么 Redis 重启时会检测是否存在部分执行的事务命令,并且利用 AOF 记录删除执行的部分命令。
Redis 事务,不同于很多 Database 的设计,不支持回滚 (Rollback),即事务中的某一条命令失败以后,其他的命令会照常执行。这样显然会造成不可预测的数据状态,但 Redis 在这里为了使其内部实现更加简单,运行更加快速,牺牲了回滚功能。由于 Redis 的命令失败只会出现在语法以及数据格式出错时才会发生,此类错误能比较容易的在开发阶段而不是实际运行中发现,这个取舍仍具有较强的合理性。
2. 内存回收
2.1 回收失效 (Expired) 数据
在写入 Redis 时,我们可以给键值对一个失效的时间。如果某一个失效键被访问了,那么 Redis 会将其踢出。
此外 Redis 还有一个有意思的机制用来去除那些再也没有被访问过的失效键。它每秒进行10次下列操作:
- 从带有失效时间的键列表(不一定已经失效)里取出20个随机的键
- 删除失效的键值对
- 如果超过25%的键已经失效,那么回到第一步再次操作。
这个机制是运用随机删除的方法保证失效键的比例在25%左右的同时,不需要维护一个失效键列表。
2.2 淘汰 (Eviction)
在前一篇文章中,我们仔细讨论了 Memcached 的 LRU Cache。下面我们来介绍 Redis 更为丰富的淘汰机制。
2.2.1 淘汰策略 (Eviction Policy)
Redis 在支持多种LRU的变种的同时,提供一系列的淘汰策略的选择。
- No Eviction 不淘汰
- All Keys LRU 传统意义的 LRU
- Volatile LRU 只对有失效时间的键值对进行 LRU 淘汰
- All Keys Random 随机淘汰
- Voltaile Random 只对有失效时间的键值对进行随机淘汰
- Voltaile TTL 只对有失效时间的键值对进行淘汰,优先选择 TTL 较短的
- All Keys LFU (Least Frequently Used) 使用频率最低的先淘汰
- Voltaile LFU 只对有失效时间的键值对进行淘汰,使用频率最低的先淘汰
2.2.2 LRU

Redis 采取了近似 LRU 的算法,它会随机找到一定数量的键,踢出其中最合适的。这样的设计相比绝对意义上的 LRU 会更省内存,并且在测试中可以足够地近绝对意义的 LRU。
2.2.3 LFU
Redis 类似的采用了近似 LFU,它使用称为 Morris Counter 的概率计数器,每个键只需几个 bit 就能估算它的使用频率,结合一定的 Decay 周期使计数器随时间减小,直到不再被认为是高频率。
2.2.4 淘汰触发
一旦系统发现内存超过了预先设置的 maxmemory,它就会根据淘汰策略开始踢出数据,直到内存回到预设范围内。正因为这个机制,Redis 使用的内存是可以超过预设值的,甚至在大量写入的情况下,可以超过预设值相当一部分。
3. 分区 (Partition)
我们回顾一下为什么要做分区 - 只有分区能够让我们使用更多机器的资源,包括内存,处理器和带宽。
3.1 分区方案
- 按照固定范围分区 - 比如选取用户 0-100 给机器 A,101-200 给机器 B。不常用。
- 哈希分区 - 比较常用的分区方案,Consistent Hashing 就是其中一种更适合自动加减机器的方案。
3.2 分区实现
可以分为三类,Redis 可以选用任意一类。
- 客户端分区 - 客户端承担选取正确的 Redis Node 的责任
- 服务器代理 (Proxy) 辅助分区 - 使用代理做中间人选取正确的 Redis Node
- 查询路由 (Query routing) - 随机将查询命令发给任意节点,该节点会将信息转发到正确的 节点。
3.3 官方分区实现
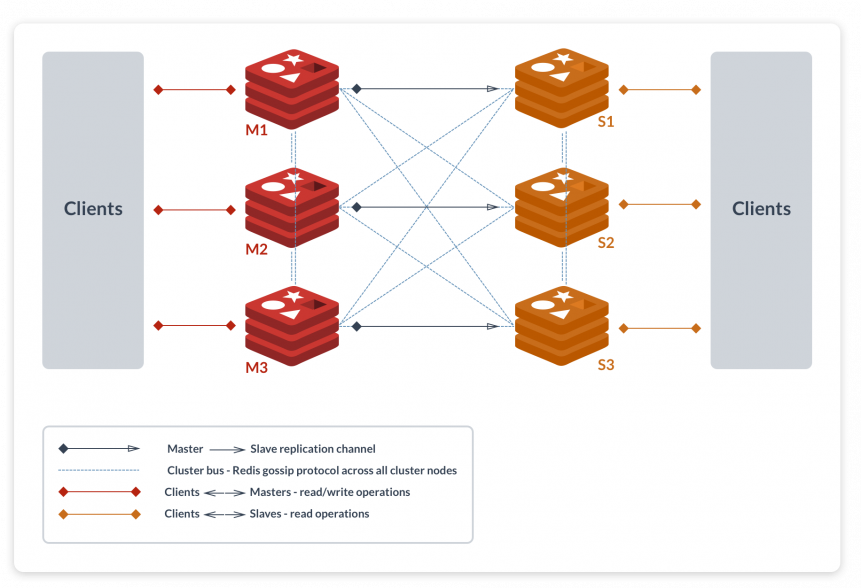
3.3.1 分区方案
Redis Cluster 是官方支持的分区方案,提供了自动化的分片 (sharding) 支持并且可以在只有部分节点工作的情况下提供服务。我们可以优先选用,它混合了客户端分区和查询路由。
分区方案在 consistent hashing 基础上做了优化,采用了跟 Cassandra 类似的方案。做法是在将 Redis 节点 consistent hash 到 Hash Slot 或者更通俗地讲叫 Virtual Node,而不是物理节点。通过引入多一层的间接关系,使得节点分配更加灵活。
3.3.2 数据备份 (Replication)
Redis Cluster 的每个 Hash Slot 都有可能会宕机,在这个情况下我们就需要引入 Master-slave 模型来为每一个 Hash Slot 做一个或者多个备份。当 Master 宕机之后可以将 Slave promote 称为新的 Master。值得注意的是,这个数据备份模式和 Cassandra 将备份数据部署到相邻节点是有区别的。
3.3.3 性能和一致性的权衡 (Performance & Consistency Tradeoff)
Redis Cluster 为了更好的性能,不保证一致性。主要原因是 Redis Node 在将 Master 数据复制到 Slave 之前就会向 Client 返回成功。如果在 Slave 获得数据之前 Master 宕机,那么这份更新就会丢失。
4. 可用性 (Availability)
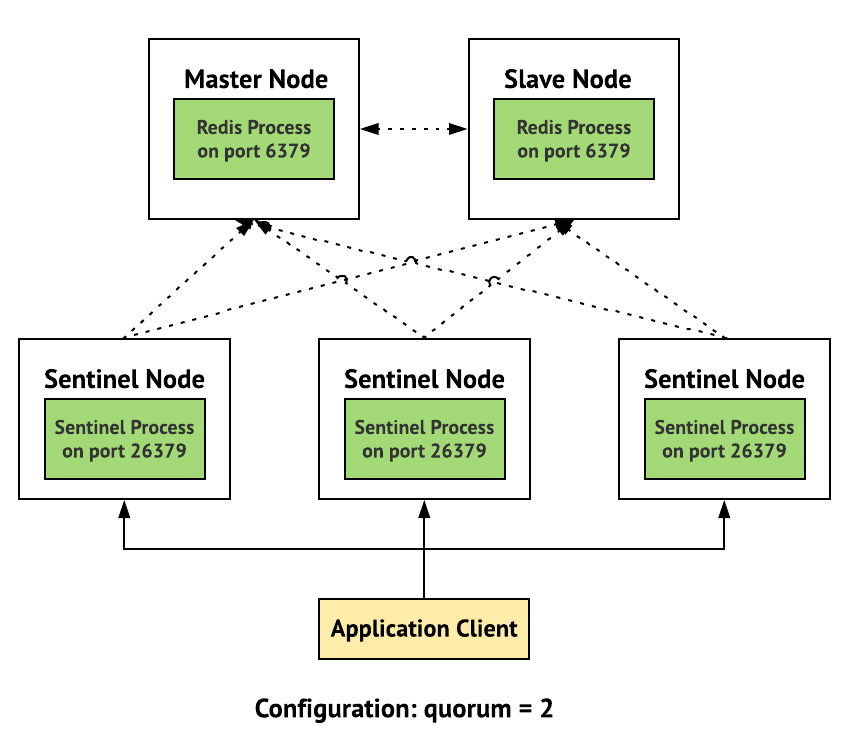
Redis Sentinel 提供了 Redis 的高可用性选择。它提供以下服务:
- 监测
- 警报
- 故障转移 (Failover) - 比如自动 promote Slave
- 服务发现 (Service Discovery) - 帮助 Client 找到服务器地址,特别是在 Failover 发生之后
5. 参考资料
- Carl Zulauf. (2017). Memcached vs Redis: Direct Comparison
- Salvatore Sanfilippo. (2015). Clarifications about Redis and Memcached
- Salvatore Sanfilippo. (2010). On Redis, Memcached, Speed, Benchmarks and The Toilet
- Salvatore Sanfilippo. (2012). Redis persistence demystified
- Salvatore Sanfilippo. (2019). Replication
- Aruzan. (2017). Which one is better, hash slot or consistent hashing?
- Tanyboye. (2018). 常见的Redis面试题及分布式集群讲解
- Redis.io. Redis Persistence
- Redis.io. Redis Expire
- Redis.io. Using Redis as an LRU cache
- Redis.io. Redis Cluster Specification
- Redis.io. Partitioning: how to split data among multiple Redis instances
- Redis.io. Redis Sentinel Documentation
- Redis.io. Redis Transactions